
Lecture 19: Linear Regression - Diagnostics#
Note
In this lecture, we will perform diagnostics, starting with preliminary diagnostics using a scatter plot, regression diagnostics by reading summary outputs, and post-regression diagnostics using residuals plot.
# Load necessary libraries
library(ggplot2)
library(dplyr)
options(repr.plot.width = 12, repr.plot.height = 8)
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
# 2024 ITUS Household Data (processed)
url <- "https://raw.githubusercontent.com/anmpahwa/CE5540/refs/heads/main/resources/ITUS_HHD_DT.csv"
data <- read.csv(url) # Loading Data
Ex-Ante Diagnostics#
Before fitting a linear regression model, it’s helpful to explore the realtionship between endogenous and exogenous variables. For instance, a pair-wise scatter plot along with correlation analysis can reveal the direction, form, and strength of the relationship, as well as the presence of outliers.
# Scatter Plot
ggplot(data, aes(x = household_size, y = total_expenditure)) +
geom_point(color = "steelblue", size = 2) +
labs(
title = "Household Size vs Monthly Expenditure",
x = "Household Size",
y = "Monthly Expenditure (₹)"
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
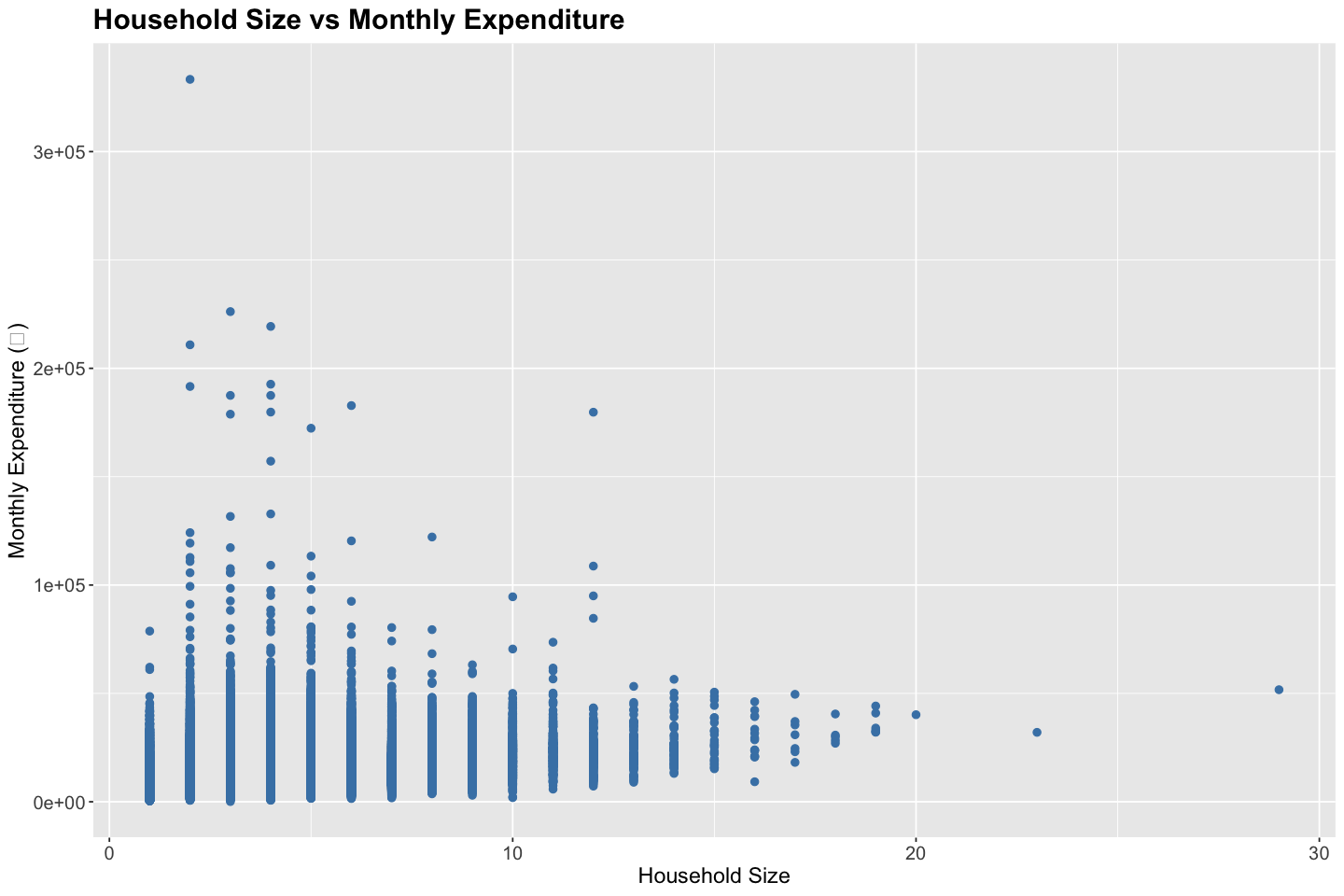
# Correlation Analysis
correlations <- cor(data$household_size, data$total_expenditure)
cat("Correlation between household size and monthly expenditure:", round(correlations, digits = 3), "\n")
Correlation between household size and monthly expenditure: 0.342
Model Diagnostics#
Once we fit a linear regression model, we assess its quality and the reliability of the estimates using summary statistics
Summary Statistics#
Sum of Squared Errors (SSE) captures the total deviation of the predicted values from the actual observed values - \(\text{SSE} = \sum_i (Y_i - \hat{Y}_i)^2\)
Sum of Squares Total (SST) captures the total variation in the dependent variable around its mean - \(\text{SST} = \sum_i (Y_i - \bar{Y})^2\)
Sum of Squares Regression (SSR) captures the variation explained by the model - \(\text{SSR} = \sum_i (\hat{Y}_i - \bar{Y})^2\)
R-squared (\(R^2\)) captures the proportion of total variation explained by the model - \(R^2 = \text{SSR} / \text{SST}\)
Adjusted R-squared (\(\bar{R}^2\)) captures the proportion of total variation explained by the model, penalizing for the number of predictors - \(\bar{R}^2 = 1 - \frac{n - 1}{n - k - 1} (1 - R^2)\)
Residual Standard Error (RSE) captures the average prediction error in the units of the response variable - \(\text{RSE} = \sqrt{\text{SSE} / (n - k - 1)}\)
Note
Sum of Squares Total equals the Sum of Squares Regression plus Sum of Squares Error - \(SST = SSR + SSE\)
Hypothesis Tests#
Test of Significane for Individual Coefficients: Each coefficient is tested against the null hypothesis \(H_o: \beta_j = 0\) using the t-test statistics \(t = \hat{\beta}_j / \text{SE}(\hat{\beta}_j)\)
Test of Significant for the Overall Model: The entire model is tested against the null hypothesis \(H_o: \beta_j = 0 \ \forall \ j\) using the F-test statistic \(F = (n - k - 1) \times \text{SSR} / (k \times \text{SSE})\)
Tip
Given, \(\text{Var}(\epsilon) = \sigma^2 I\), we get, \(\text{Var}(\hat{\beta}_j) = \sigma^2 [(X^\top X)^{-1}]_{jj}\)
# Model: Household Size vs Monthly Expenditure
model <- lm(total_expenditure ~ household_size, data = data)
# Summary
summary(model)
Call:
lm(formula = total_expenditure ~ household_size, data = data)
Residuals:
Min 1Q Median 3Q Max
-21252 -4667 -1678 2918 322938
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7524.97 44.86 167.7 <2e-16 ***
household_size 1434.98 10.54 136.1 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7338 on 139485 degrees of freedom
Multiple R-squared: 0.1173, Adjusted R-squared: 0.1173
F-statistic: 1.853e+04 on 1 and 139485 DF, p-value: < 2.2e-16
# Statistics
sst <- sum((data$total_expenditure - mean(data$total_expenditure))^2)
ssr <- sum((model$fitted.values - mean(data$total_expenditure))^2)
sse <- sum((data$total_expenditure - model$fitted.values)^2)
rse <- sqrt(sse / (nrow(data) - 2))
Rsquared <- ssr / sst
AdjRsquared <- 1 - (1 - Rsquared) * (nrow(data) - 1) / (nrow(data) - 2)
cat("SST :", round(sst, 2), "\n")
cat("SSR :", round(ssr, 2), "\n")
cat("SSE :", round(sse, 2), "\n")
cat("RSE :", round(rse, 2), "\n")
cat("R-squared :", round(Rsquared, 3), "\n")
cat("Adjusted R-squared:", round(AdjRsquared, 3), "\n")
SST : 8.509048e+12
SSR : 997912101887
SSE : 7.511136e+12
RSE : 7338.19
R-squared : 0.117
Adjusted R-squared: 0.117
Ex-Post Diagnostics#
After fitting a linear regression model, it is essential to evaluate whether the underlying model assumptions are valid. These assumptions include linearity of the relationship between predictors and the response, independence of residuals, homoskedasticity (constant variance of residuals), absence of multicollinearity among predictors, and the condition that the error term has a zero conditional mean. Violations of these assumptions can undermine the validity of inference from the model, including confidence intervals and hypothesis tests.
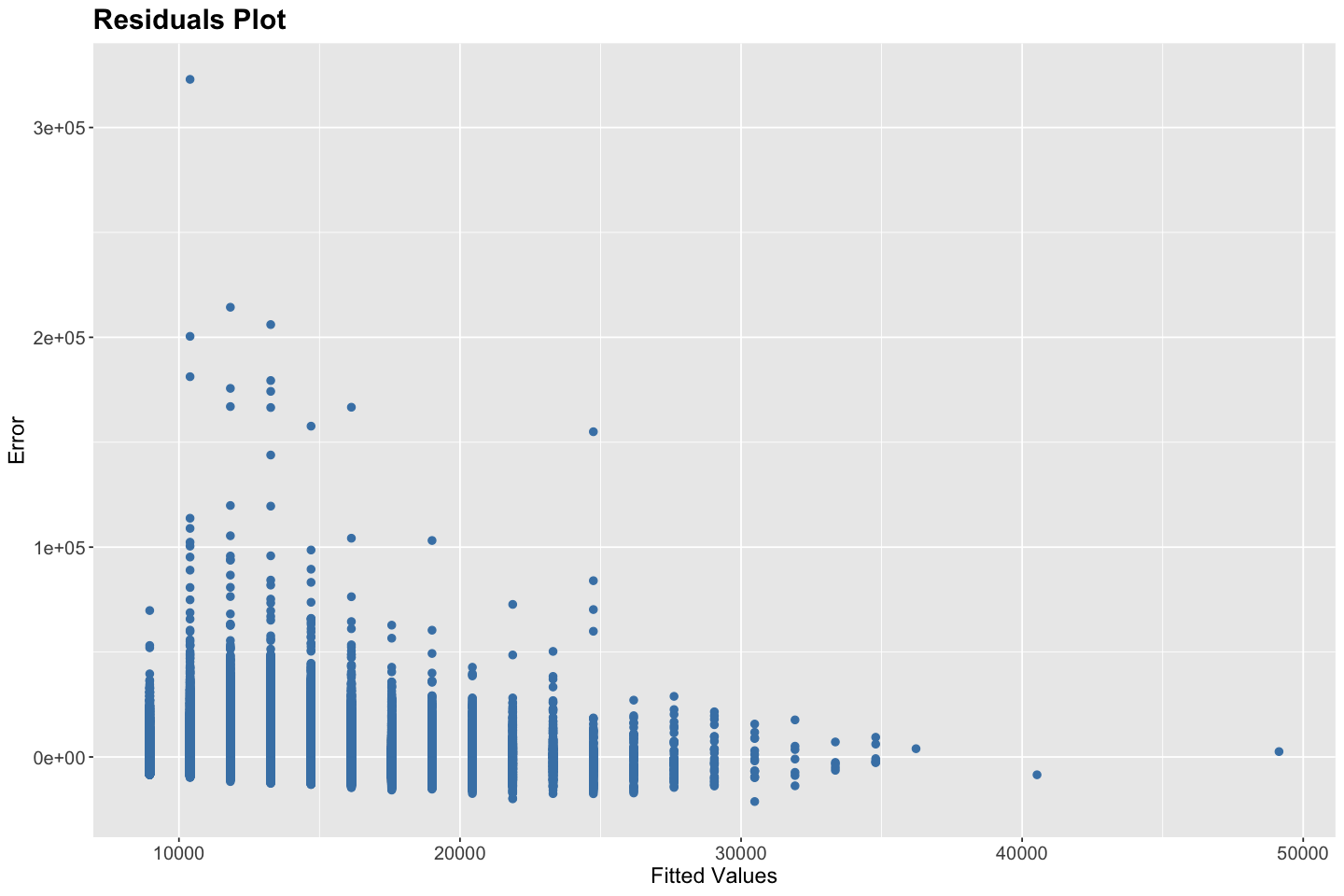
Residual diagnostics help us examine these assumptions. One of the most useful tools is the residual vs. fitted values plot. In this plot, residuals (i.e., the differences between observed and predicted values) are plotted on the y-axis against the model’s fitted values on the x-axis. Ideally, the residuals should be randomly scattered around the horizontal axis (zero), with no discernible pattern. This randomness indicates that the model has appropriately captured the structure in the data, supporting the assumptions of linearity and homoskedasticity. If the residual plot exhibits a U-shape or inverted U-shape, it suggests non-linearity. If the spread of residuals increases or decreases across the range of fitted values, it indicates heteroskedasticity. Clusters or non-random structure may also suggest model mis-specification or omitted variables. Additionally, the presence of extreme or isolated points may point to outliers or influential observations that unduly affect the model fit.
If diagnostics reveal that assumptions are violated, various remedies are available. For non-linearity, one might apply transformations (e.g., logarithmic, polynomial) to the predictors or use non-linear models. In the case of heteroskedasticity, robust standard errors, weighted least squares, or variance-stabilizing transformations may be appropriate. If residuals are not normally distributed, bootstrapping methods can be employed for inference. In time-series data, autocorrelation in residuals can be detected using the Durbin-Watson statistic, and corrected using models like ARIMA or GLS. Finally, multicollinearity among predictors can be diagnosed using variance inflation factors (VIFs); remedies include removing redundant predictors or using dimensionality reduction techniques.
# Regression Plot
ggplot(data, aes(x = household_size, y = total_expenditure)) +
geom_point(color = "steelblue", size = 2) +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE, color = "darkred", linewidth = 1.2) +
labs(
title = "Regression Plot",
x = "Household Size",
y = "Monthly Expenditure (₹)"
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
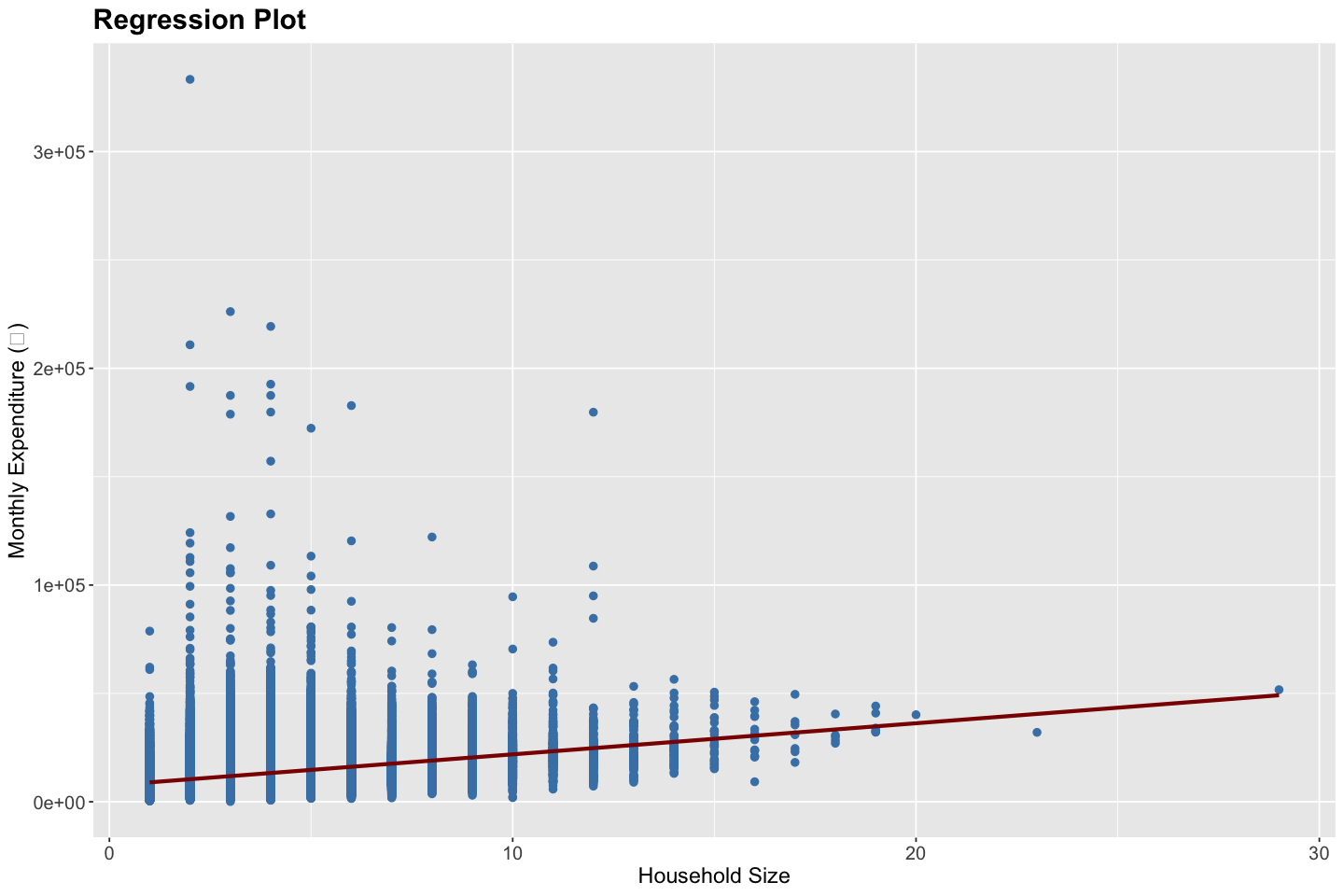
# Residuals Plot
data$fitted <- fitted(model)
data$resid <- resid(model)
ggplot(data, aes(x = fitted, y = resid)) +
geom_point(color = "steelblue", size = 2) +
labs(
title = "Residuals Plot",
x = "Fitted Values",
y = "Error"
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
Linearity: Moderately Violated - The regression plot shows a generally positive trend between household size and expenditure. However, the wide vertical spread and potential non-linear behavior at lower household sizes indicate that the relationship may not be strictly linear. Hence, a transformation (e.g., log) or a non-linear model (e.g., spline or polynomial) may be more appropriate.
Independence: Satisfied - Since the households were randomly and independently sampled, this assumption holds.
Homoskedasticity: Violated - The residuals plot exhibits a funnel-shaped pattern, where the variance of residuals is higher for lower fitted values and reduces as fitted values increase. This indicates heteroskedasticity, which leads to inefficient estimates and unreliable standard errors.
No Multicollinearity: Not Applicable - Since the model includes only one independent variable (household size), multicollinearity is not a concern here.
Zero Conditional Mean of Errors: Possibly Violated - While the residuals center around zero, the systematic heteroskedastic pattern suggests that the error term may depend on the fitted values (and thus on the predictor). This may imply omitted variable bias or model misspecification.