
Lecture 14: Multivariate Data#
Note
In the first few lectures of this course, we explored measures of location, dispersion, and shape to communicate the characteristics of the single variable data. In this lecture, we will explore means of communicating characteristics of multivariate data.
Introduction#
Multivariate data involves making two or more measurements per entity. For instance, the 2024 Indian Time Use Survey captures gender, age, marital status, education level, and employment status, among other identifier variables (NSS region, district, stratum, sub-stratum, etc.), for each individual. Further, the 2024 Indian Time Use Survey captures household size, religion, social group, land possesed, and monthly expenditure, among others including identifier variables (NSS region, district, stratum, sub-stratum, etc.), for each household.
# Load necessary libraries
library(ggplot2)
library(dplyr)
options(repr.plot.width = 12, repr.plot.height = 8)
# 2024 ITUS Individual Data (processed)
url <- "https://raw.githubusercontent.com/anmpahwa/CE5540/refs/heads/main/resources/ITUS_IND_DT.csv"
data <- read.csv(url) # Loading Data
str(data) # Data Structure
'data.frame': 454192 obs. of 22 variables:
$ Unique_ID : chr "2024-30010-1-241-17-13-11-2-2420-4-1-1" "2024-30010-1-241-17-13-11-2-2420-4-10-1" "2024-30010-1-241-17-13-11-2-2420-4-10-2" "2024-30010-1-241-17-13-11-2-2420-4-11-1" ...
$ Unique_HH_ID : chr "2024-30010-1-241-17-13-11-2-2420-4-1" "2024-30010-1-241-17-13-11-2-2420-4-10" "2024-30010-1-241-17-13-11-2-2420-4-10" "2024-30010-1-241-17-13-11-2-2420-4-11" ...
$ time_of_year : int 2 2 2 2 2 2 2 2 2 2 ...
$ day_of_week : int 2 2 2 6 6 6 6 6 1 1 ...
$ sector : int 1 1 1 1 1 1 1 1 1 1 ...
$ region : int 2 2 2 2 2 2 2 2 2 2 ...
$ district_population: int 1642268 1642268 1642268 1642268 1642268 1642268 1642268 1642268 1642268 1642268 ...
$ gender : int 1 1 2 1 2 1 2 2 1 2 ...
$ age : int 45 28 25 45 43 17 21 18 45 42 ...
$ marital_status : int 1 2 2 2 2 1 1 1 2 2 ...
$ education_level : int 11 5 4 5 1 6 4 6 1 4 ...
$ employment_status : int 31 51 92 11 92 51 92 11 11 11 ...
$ family_structure : num 0 0.333 0.333 0.4 0.4 0.4 0.4 0.4 0.429 0.429 ...
$ household_size : int 1 3 3 5 5 5 5 5 7 7 ...
$ religion : int 1 1 1 1 1 1 1 1 1 1 ...
$ social_group : int 3 3 3 3 3 3 3 3 3 3 ...
$ land_possessed : int 1 2 2 2 2 2 2 2 5 5 ...
$ total_expenditure : int 7142 8322 8322 12373 12373 12373 12373 12373 11525 11525 ...
$ dwelling_unit : int 1 1 1 1 1 1 1 1 1 1 ...
$ dwelling_structure : int 3 3 3 3 3 3 3 3 3 3 ...
$ weight : int 208857 208857 208857 208857 208857 208857 208857 208857 208857 208857 ...
$ shopping_choice : int 0 0 0 0 0 0 0 0 0 0 ...
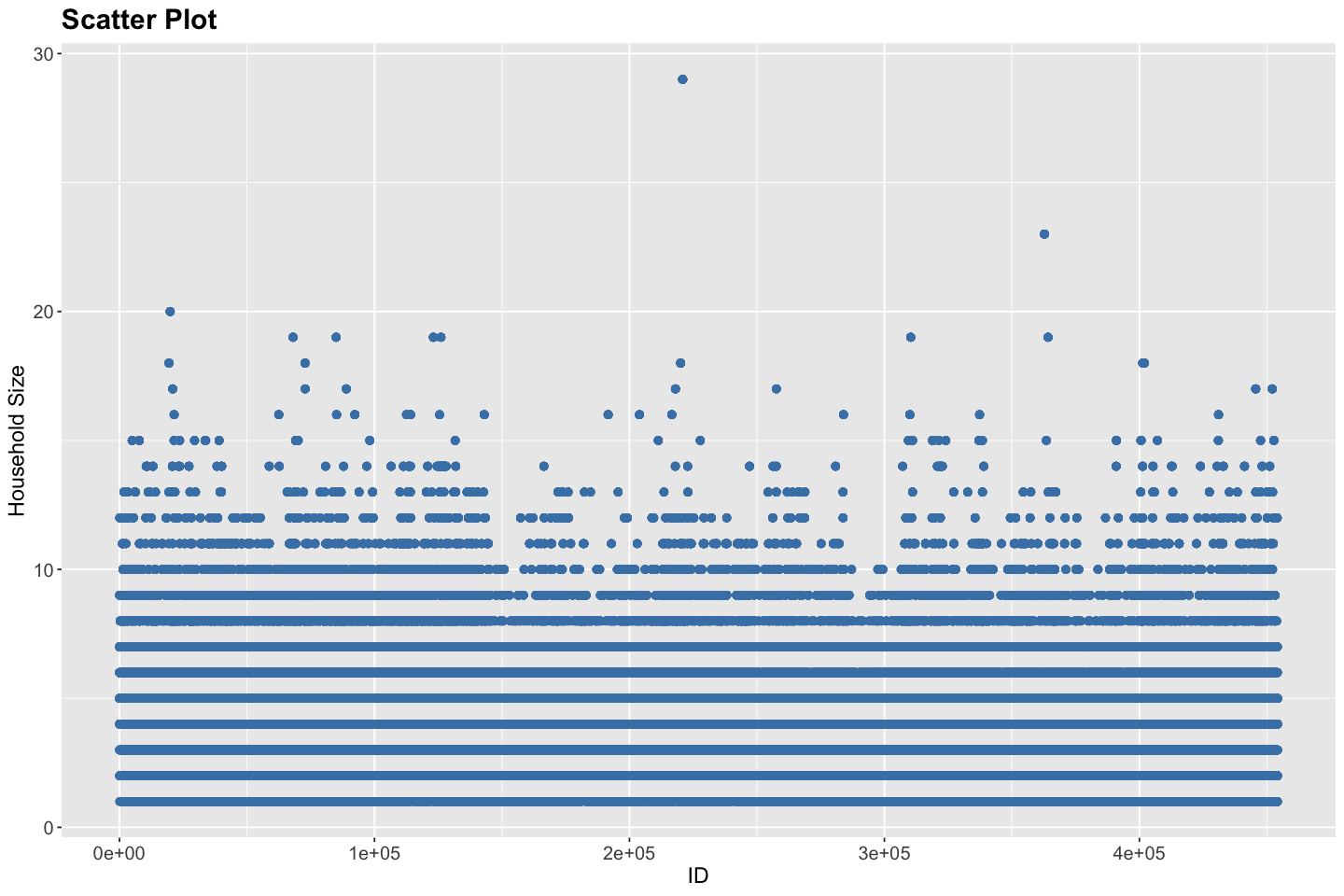
# Scatter Plot for Household Size
ggplot(data, aes(x = seq_along(Unique_ID), y = household_size)) +
geom_point(color = "steelblue", size = 2) +
labs(
title = "Scatter Plot",
x = "ID",
y = "Household Size",
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
plot.subtitle = element_text(size = 14),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
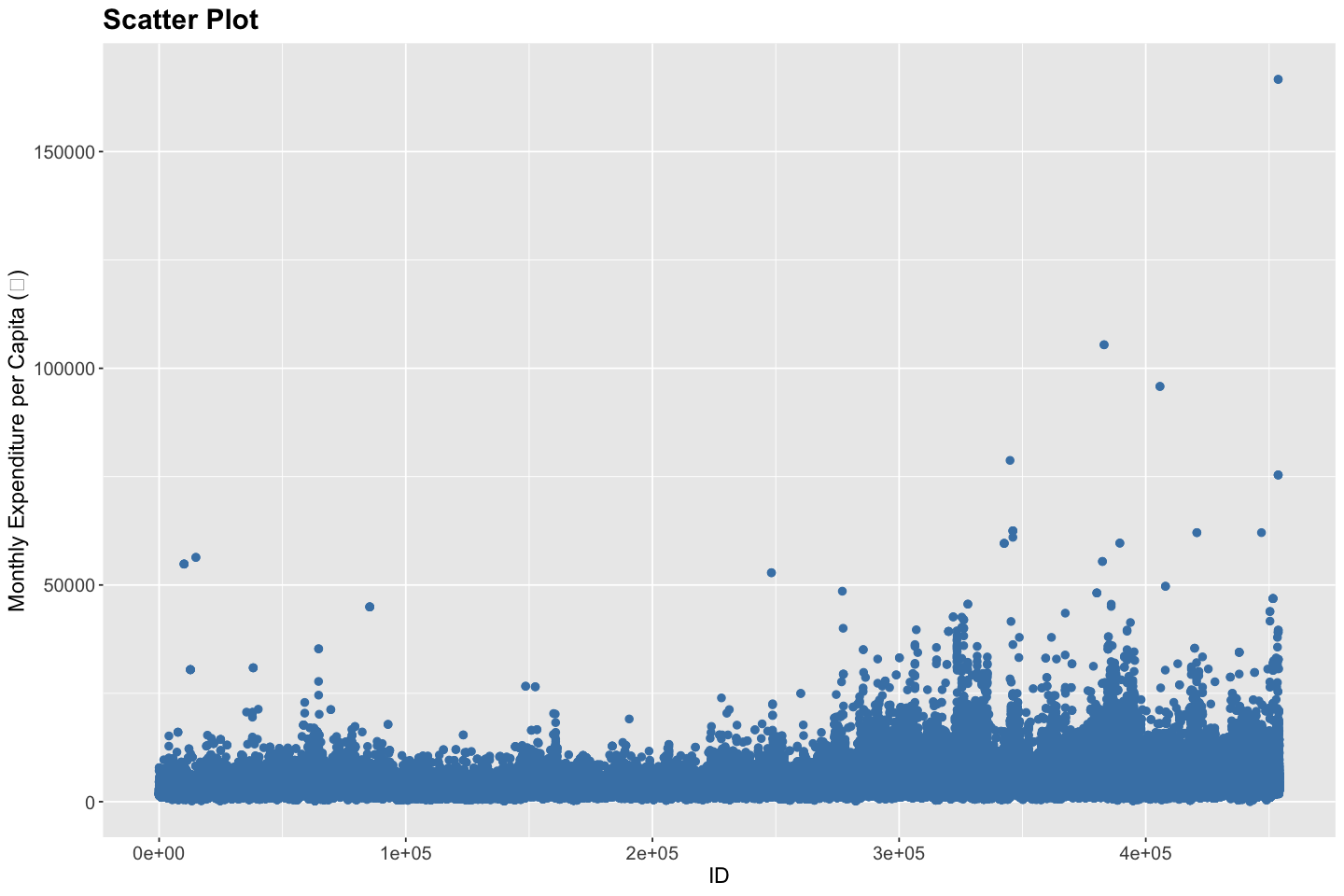
# Scatter Plot for Monthly Expenditure per Capita (₹)
ggplot(data, aes(x = seq_along(Unique_ID), y = total_expenditure / household_size)) +
geom_point(color = "steelblue", size = 2) +
labs(
title = "Scatter Plot",
x = "ID",
y = "Monthly Expenditure per Capita (₹)"
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
plot.subtitle = element_text(size = 14),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
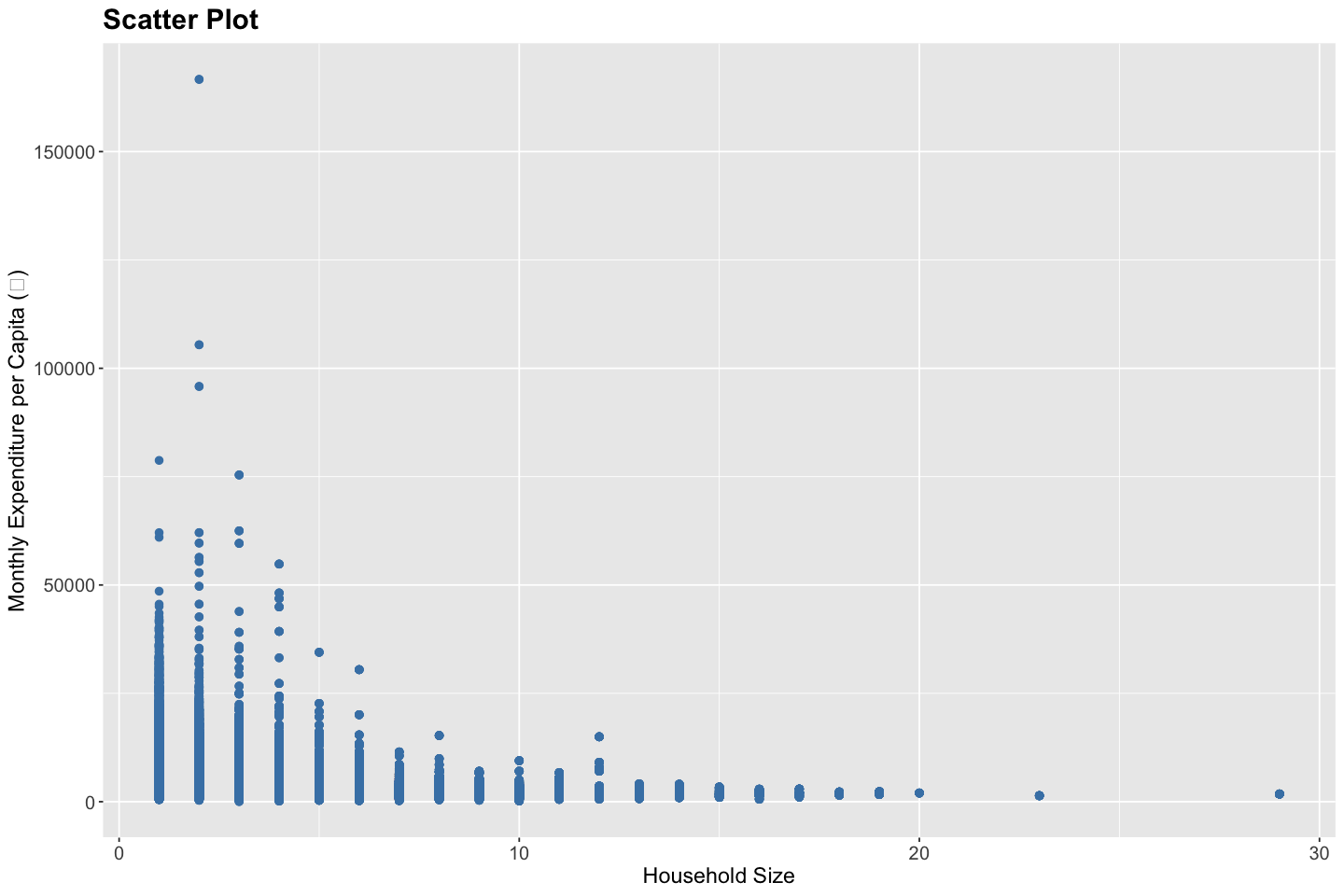
# Scatter plot for Monthly Expenditure per Capita vs. Household Size
ggplot(data, aes(x = household_size, y = total_expenditure / household_size)) +
geom_point(color = "steelblue", size = 2) +
labs(
title = "Scatter Plot",
x = "Household Size",
y = "Monthly Expenditure per Capita (₹)"
) +
theme(
plot.title = element_text(size = 18, face = "bold"),
plot.subtitle = element_text(size = 14),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12)
)
Test Yourself
Through these scatter plots, answer the following questions,
What is the largest household size?
What is the highest monthly expenditure per capita?
What is the highest monthly expenditure for a single-person household?
In addition to rudimentary exploratory analysis, these scatter plots can also help identify,
Linearity and Non-linearity#
Linearity refers to the situation where the relationship between the predictor variable \(X\) and the response variable \(Y\) can be well approximated by a straight line. In a scatter plot, this appears as a cloud of points roughly forming a linear trend. Linear relationships are foundational in many statistical models, including simple and multiple linear regression. Non-linearity, on the other hand, occurs when the relationship between \(X\) and \(Y\) cannot be captured adequately by a straight line. This could manifest as curves, exponential growth or decay, plateaus, or other complex patterns. Identifying non-linearity is essential because applying a linear model to non-linear data can lead to biased estimates and misleading inferences. Techniques such as polynomial regression, splines, or transformation of variables are often used to handle non-linearity.
Homoscedasticity and Heteroscedasticity#
Homoscedasticity describes a scenario in which the variability of the response variable \(Y\) remains constant across all levels of the predictor \(X\). In graphical terms, if you draw vertical slices through a scatter plot, the spread of the Y-values should be roughly equal across these slices. Homoscedasticity is a key assumption in linear regression, as violations can lead to inefficient estimates and invalid standard errors. In contrast, heteroscedasticity occurs when the variance of \(Y\) changes with \(X\) — for example, increasing or decreasing as \(X\) increases. This fan-shaped or funnel-shaped pattern in a scatter plot signals heteroscedasticity. It often arises in income data, where higher-income groups tend to show greater variation in expenditure, for instance. If present, robust regression methods or variance-stabilizing transformations may be required.
Outliers#
Outliers are observations that lie far from the general pattern of the data. They can arise due to data entry errors, measurement anomalies, or genuine variability in the population. Statistically, outliers are often defined as points lying more than 1.5 times the interquartile range (IQR) from the quartiles, or several standard deviations away from the mean. Outliers can have a disproportionate influence on model estimates, especially in methods like least squares regression, which are sensitive to extreme values. While not all outliers are problematic, their presence should prompt further investigation — they might reveal interesting phenomena, data quality issues, or the need for robust modeling techniques that down-weight their influence.
Test Yourself
The relation between household size and monthly expenditure per capita is linear.
The monthly expenditure per capita is heteroscedastic with respect to household size.
The monthly expenditure per capita contains outliers.
Tip
In the next few lectures, we will explore such visualization tools - a critical part of the analytical workflow, to uncover patterns and communicate insights more effectivey, particularly for multivariate data. These visual data summaries will enable us to detect trends and spot anomalies, serving as a foundation for more advanced data analysis.